publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- Arxiv
 OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory SynthesisZhuofeng Li * , Dongfu Jiang * , Xueguang Ma * , and 7 more authorsIn arxiv preprint, Mar 2026
OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory SynthesisZhuofeng Li * , Dongfu Jiang * , Xueguang Ma * , and 7 more authorsIn arxiv preprint, Mar 2026
Training deep research agents requires long-horizon trajectories that interleave search, evidence aggregation, and multi-step reasoning. However, existing data collection pipelines typically rely on proprietary web APIs, making large-scale trajectory synthesis costly, unstable, and difficult to reproduce. We present OpenResearcher, a reproducible pipeline that decouples one-time corpus bootstrapping from multi-turn trajectory synthesis and executes the search-and-browse loop entirely offline using three explicit browser primitives—search, open, and find—over a 15M-document corpus. Using GPT-OSS-120B as the teacher model, we synthesize over 97K trajectories, including a substantial long-horizon tail with 100+ tool calls. After supervised fine-tuning a 30B-A3B backbone, we achieve 54.8% accuracy on BrowseComp-Plus, a +34.0 point improvement over the base model, while remaining competitive on BrowseComp, GAIA, and xbench-DeepSearch. The offline, fully instrumented environment also enables controlled analysis, revealing practical insights into deep research pipeline design. We release the pipeline, synthesized trajectories, model checkpoints, and the offline search environment.
@inproceedings{li2026openresearcher, title = {OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis}, author = {Li, Zhuofeng and Jiang, Dongfu and Ma, Xueguang and Zhang, Haoxiang and Nie, Ping and Zhang, Yuyu and Zou, Kai and Xie, Jianwen and Zhang, Yu and Chen, Wenhu}, booktitle = {arxiv preprint}, month = mar, year = {2026}, github = {TIGER-AI-Lab/OpenResearcher}, huggingface = {https://huggingface.co/OpenResearcher}, twitter = {https://x.com/zhuofengli96475/status/2036475211063648414}, selected = true, num_co_first_author = {5}, } - ICLR 2026
 ImagenWorld: Stress-Testing Image Generation Models with Explainable Human Evaluation on Open-ended Real-World TasksSamin Mahdizadeh Sani , Max Ku , Nima Jamali , and 23 more authorsIn ICLR 2026, Jan 2026
ImagenWorld: Stress-Testing Image Generation Models with Explainable Human Evaluation on Open-ended Real-World TasksSamin Mahdizadeh Sani , Max Ku , Nima Jamali , and 23 more authorsIn ICLR 2026, Jan 2026We introduce ImagenWorld, a benchmark of 3.6K condition sets spanning six core tasks (generation and editing, with single or multiple references) and six topical domains (artworks, photorealistic images, information graphics, textual graphics, computer graphics, and screenshots). The benchmark is supported by 20K fine-grained human annotations and an explainable evaluation schema that tags localized object-level and segment-level errors, complementing automated VLM-based metrics. Our large-scale evaluation of 14 models yields several insights: (1) models typically struggle more in editing tasks than in generation tasks, especially in local edits. (2) models excel in artistic and photorealistic settings but struggle with symbolic and text-heavy domains such as screenshots and information graphics. (3) closed-source systems lead overall, while targeted data curation narrows the gap in text-heavy cases. (4) modern VLM-based metrics achieve Kendall accuracies up to 0.79, approximating human ranking, but fall short of fine-grained, explainable error attribution.
@inproceedings{sani2026imagenworld, title = {ImagenWorld: Stress-Testing Image Generation Models with Explainable Human Evaluation on Open-ended Real-World Tasks}, author = {Sani, Samin Mahdizadeh and Ku, Max and Jamali, Nima and Sani, Matina Mahdizadeh and Khoshtab, Paria and Sun, Wei-Chieh and Fazel, Parnian and Tam, Zhi Rui and Chong, Thomas and Chan, Edisy Kin Wai and Tsang, Donald Wai Tong and Hsu, Chiao-Wei and Lam, Ting Wai and Ng, Ho Yin Sam and Chu, Chiafeng and Mak, Chak-Wing and Wu, Keming and Wong, Hiu Tung and Ho, Yik Chun and Ruan, Chi and Li, Zhuofeng and Fang, I-Sheng and Yeh, Shih-Ying and Cheng, Ho Kei and Nie, Ping and Chen, Wenhu}, booktitle = {ICLR 2026}, month = jan, year = {2026}, selected = true, }

2025
- ICLR 2026 Oral
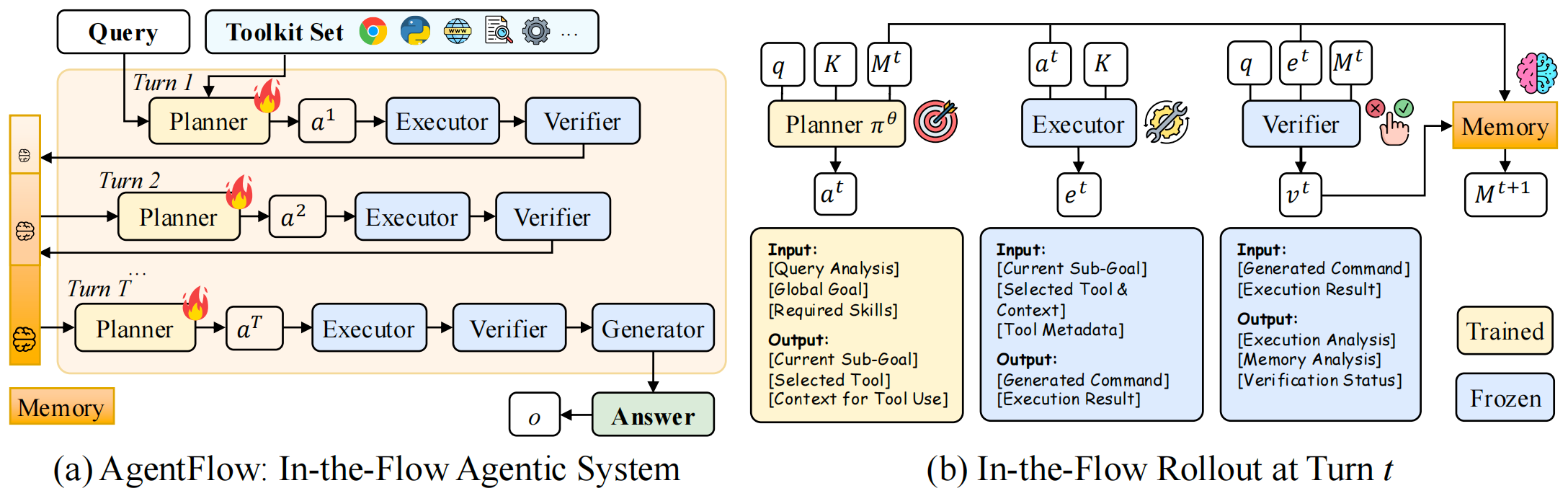 In-The-Flow Agentic System Optimization for Effective Planning and Tool UseZhuofeng Li * , Haoxiang Zhang * , Seungju Han , and 6 more authorsIn ICLR 2026 Oral & NeurIPS 2025 Workshop Best Paper Runner-up, Oct 2025
In-The-Flow Agentic System Optimization for Effective Planning and Tool UseZhuofeng Li * , Haoxiang Zhang * , Seungju Han , and 6 more authorsIn ICLR 2026 Oral & NeurIPS 2025 Workshop Best Paper Runner-up, Oct 2025 Outcome-driven reinforcement learning has advanced reasoning in large language models (LLMs), but prevailing tool-augmented approaches train a single, monolithic policy that interleaves thoughts and tool calls under full context; this scales poorly with long horizons and diverse tools and generalizes weakly to new scenarios. Agentic systems offer a promising alternative by decomposing work across specialized modules, yet most remain training-free or rely on offline training decoupled from the live dynamics of multi-turn interaction. We introduce AgentFlow, a trainable, in-the-flow agentic framework that coordinates four modules (planner, executor, verifier, generator) through an evolving memory and directly optimizes its planner inside the multi-turn loop. To train on-policy in live environments, we propose Flow-based Group Refined Policy Optimization (Flow-GRPO), which tackles long-horizon, sparse-reward credit assignment by converting multi-turn optimization into a sequence of tractable single-turn policy updates. It broadcasts a single, verifiable trajectory-level outcome to every turn to align local planner decisions with global success and stabilizes learning with group-normalized advantages. Across ten benchmarks, AgentFlow with a 7B-scale backbone outperforms top-performing baselines with average accuracy gains of 14.9% on search, 14.0% on agentic, 14.5% on mathematical, and 4.1% on scientific tasks, even surpassing larger proprietary models like GPT-4o. Further analyses confirm the benefits of in-the-flow optimization, showing improved planning, enhanced tool-calling reliability, and positive scaling with model size and reasoning turns.
@inproceedings{li2025agentflow, title = {In-The-Flow Agentic System Optimization for Effective Planning and Tool Use}, author = {Li, Zhuofeng and Zhang, Haoxiang and Han, Seungju and Liu, Sheng and Xie, Jianwen and Zhang, Yu and Choi, Yejin and Zou, James and Lu, Pan}, booktitle = {ICLR 2026 Oral & NeurIPS 2025 Workshop Best Paper Runner-up}, month = oct, year = {2025}, github = {lupantech/AgentFlow}, huggingface = {https://huggingface.co/AgentFlow}, twitter = {https://x.com/lupantech/status/1976016000345919803}, selected = true, num_co_first_author = {2}, } - Arxiv
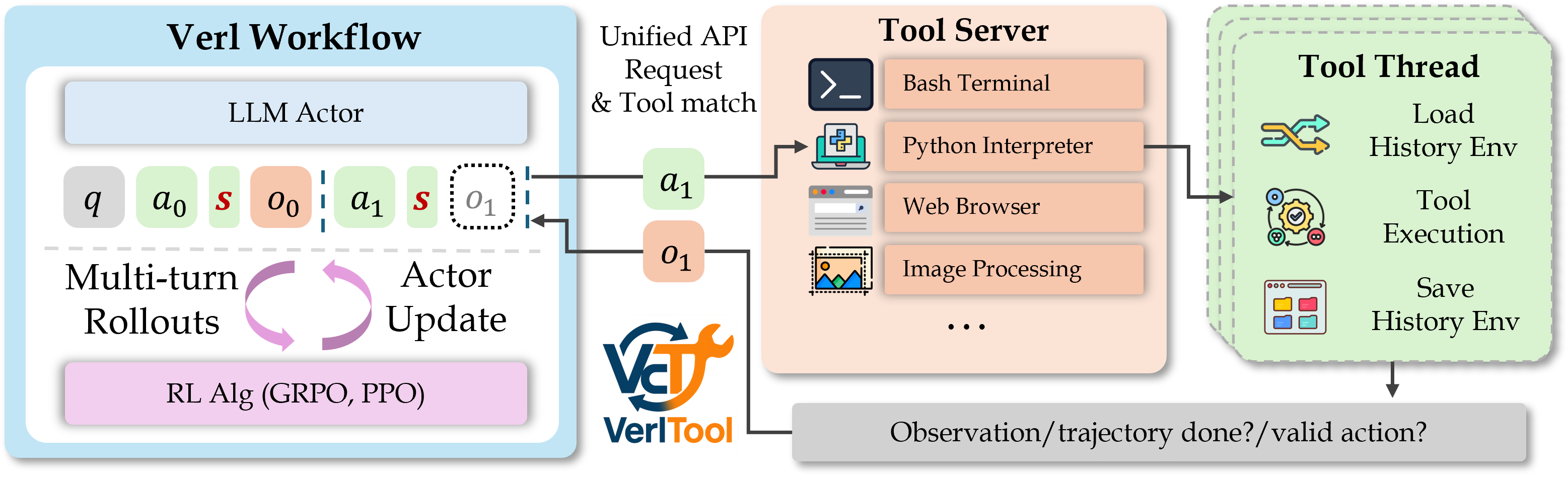 VerlTool: Towards Holistic Agentic Reinforcement Learning with Tool UseDongfu Jiang * , Yi Lu * , Zhuofeng Li * , and 9 more authorsIn arxiv preprint, Sep 2025
VerlTool: Towards Holistic Agentic Reinforcement Learning with Tool UseDongfu Jiang * , Yi Lu * , Zhuofeng Li * , and 9 more authorsIn arxiv preprint, Sep 2025 Reinforcement Learning with Verifiable Rewards (RLVR) has demonstrated success in enhancing LLM reasoning capabilities, but remains limited to single-turn interactions without tool integration. While recent Agentic Reinforcement Learning with Tool use (ARLT) approaches have emerged to address multi-turn tool interactions, existing works develop task-specific codebases that suffer from fragmentation, synchronous execution bottlenecks, and limited extensibility across domains. These inefficiencies hinder broader community adoption and algorithmic innovation. We introduce VerlTool, a unified and modular framework that addresses these limitations through systematic design principles. VerlTool provides four key contributions: (1) upstream alignment with VeRL ensuring compatibility and simplified maintenance, (2) unified tool management via standardized APIs supporting diverse modalities including code execution, search, SQL databases, and vision processing, (3) asynchronous rollout execution achieving near 2× speedup by eliminating synchronization bottlenecks, and (4) comprehensive evaluation demonstrating competitive performance across 6 ARLT domains. Our framework formalizes ARLT as multi-turn trajectories with multi-modal observation tokens (text/image/video), extending beyond single-turn RLVR paradigms. We train and evaluate models on mathematical reasoning, knowledge QA, SQL generation, visual reasoning, web search, and software engineering tasks, achieving results comparable to specialized systems while providing unified training infrastructure.
@inproceedings{jiang2025verltool, title = {VerlTool: Towards Holistic Agentic Reinforcement Learning with Tool Use}, author = {Jiang, Dongfu and Lu, Yi and Li, Zhuofeng and Lyu, Zhiheng and Nie, Ping and Wang, Haozhe and Su, Alex and Chen, Hui and Zou, Kai and Du, Chao and Pang, Tianyu and Chen, Wenhu}, booktitle = {arxiv preprint}, month = sep, year = {2025}, github = {TIGER-AI-Lab/verl-tool}, huggingface = {https://huggingface.co/papers/2509.01055}, twitter = {https://x.com/zhuofengli96475/status/1963216180438814901}, selected = true, num_co_first_author = {4}, } - CIKM 2025
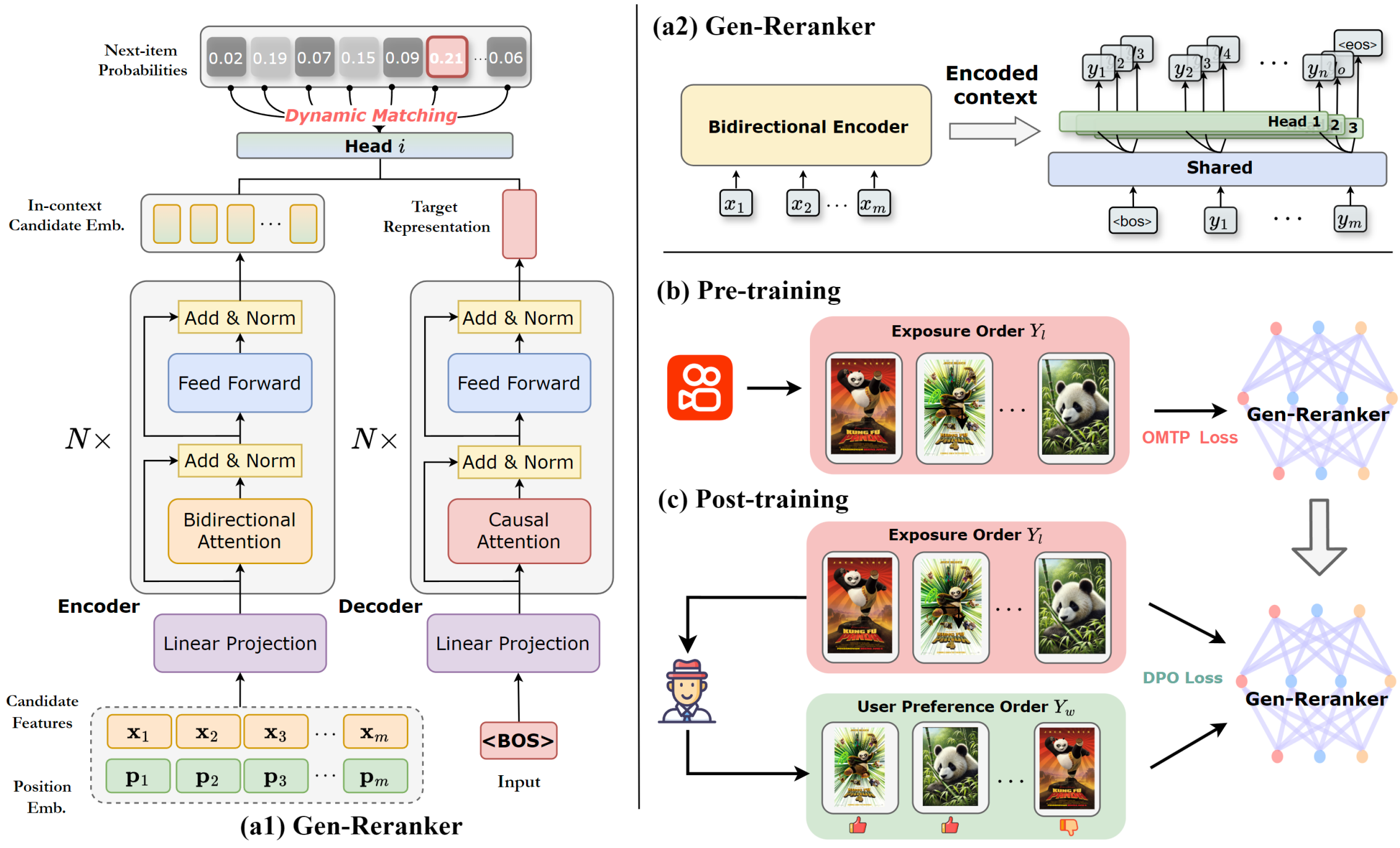 GReF: A Unified Generative Framework for Efficient Reranking via Ordered Multi-token PredictionZhijie Lin * , Zhuofeng Li * , Chenglei Dai , and 5 more authorsIn Proceedings of the 34th ACM International Conference on Information and Knowledge Management, Nov 2025
GReF: A Unified Generative Framework for Efficient Reranking via Ordered Multi-token PredictionZhijie Lin * , Zhuofeng Li * , Chenglei Dai , and 5 more authorsIn Proceedings of the 34th ACM International Conference on Information and Knowledge Management, Nov 2025In a multi-stage recommendation system, reranking plays a crucial role in modeling intra-list correlations among items. A key challenge lies in exploring optimal sequences within the combinatorial space of permutations. Recent research follows a two-stage (generator-evaluator) paradigm, where a generator produces multiple feasible sequences, and an evaluator selects the best one. In practice, the generator is typically implemented as an autoregressive model. However, these two-stage methods face two main challenges. First, the separation of the generator and evaluator hinders end-to-end training. Second, autoregressive generators suffer from inference efficiency. In this work, we propose a Unified Generative Efficient Reranking Framework (GReF) to address the two primary challenges. Specifically, we introduce Gen-Reranker, an autoregressive generator featuring a bidirectional encoder and a dynamic autoregressive decoder to generate causal reranking sequences. Subsequently, we pre-train Gen-Reranker on the item exposure order for high-quality parameter initialization. To eliminate the need for the evaluator while integrating sequence-level evaluation during training for end-to-end optimization, we propose post-training the model through Rerank-DPO. Moreover, for efficient autoregressive inference, we introduce ordered multi-token prediction (OMTP), which trains Gen-Reranker to simultaneously generate multiple future items while preserving their order, ensuring practical deployment in real-time recommender systems. Extensive offline experiments demonstrate that GReF outperforms state-of-the-art reranking methods while achieving latency that is nearly comparable to non-autoregressive models. Additionally, GReF has also been deployed in a real-world video app Kuaishou with over 300 million daily active users, significantly improving online recommendation quality.
@inproceedings{lin2025gref, title = {GReF: A Unified Generative Framework for Efficient Reranking via Ordered Multi-token Prediction}, author = {Lin, Zhijie and Li, Zhuofeng and Dai, Chenglei and Bao, Wentian and Lin, Shuai and Yu, Enyun and Zhang, Haoxiang and Zhao, Liang}, booktitle = {Proceedings of the 34th ACM International Conference on Information and Knowledge Management}, month = nov, year = {2025}, selected = true, num_co_first_author = {2}, } - TMLR 2025
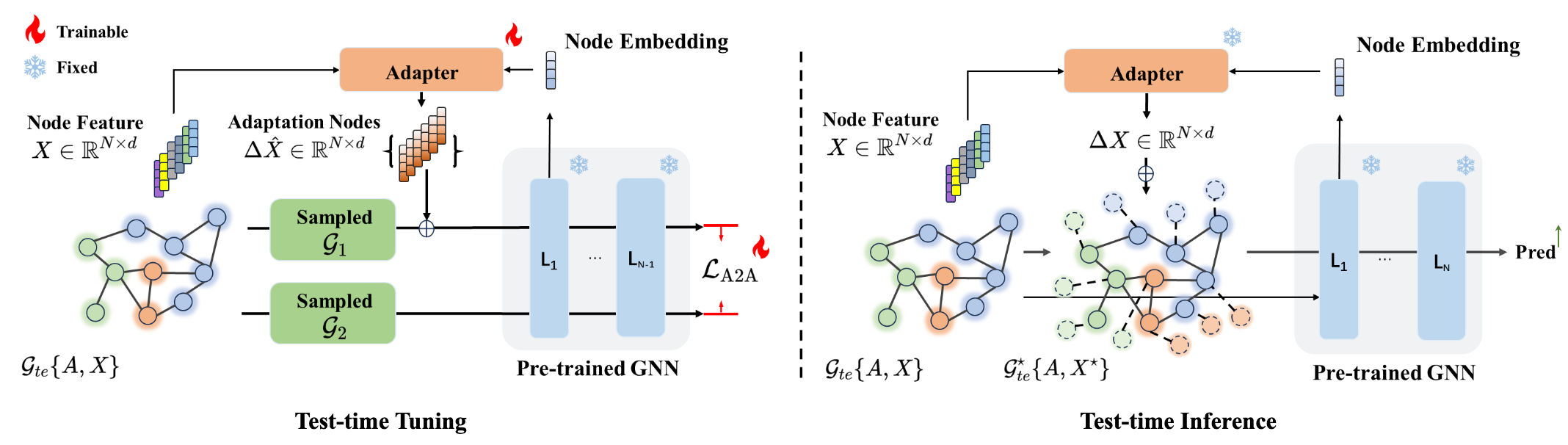 Avoiding Structural Pitfalls: Self-Supervised Low-Rank Feature Tuning for Graph Test-Time AdaptationHaoxiang Zhang * , Zhuofeng Li * , Qiannan Zhang , and 3 more authorsIn Transactions on Machine Learning Research (TMLR), Oct 2025, Oct 2025
Avoiding Structural Pitfalls: Self-Supervised Low-Rank Feature Tuning for Graph Test-Time AdaptationHaoxiang Zhang * , Zhuofeng Li * , Qiannan Zhang , and 3 more authorsIn Transactions on Machine Learning Research (TMLR), Oct 2025, Oct 2025Graph Neural Networks (GNNs) have shown impressive performance on graph-structured data, but they often struggle to generalize when facing distribution shifts at test time. Existing test-time adaptation methods for graphs primarily focus on node feature adjustments while overlooking structural information, leading to suboptimal adaptation. We propose a novel self-supervised low-rank feature tuning approach that jointly considers both node features and graph structure during test-time adaptation. Our method leverages self-supervised learning objectives and low-rank matrix factorization to efficiently adapt GNNs to new graph distributions without requiring labeled data, avoiding common structural pitfalls that plague existing approaches.
@inproceedings{zhang2025avoiding, title = {Avoiding Structural Pitfalls: Self-Supervised Low-Rank Feature Tuning for Graph Test-Time Adaptation}, author = {Zhang, Haoxiang and Li, Zhuofeng and Zhang, Qiannan and Kou, Ziyi and Li, Juncheng and Pei, Shichao}, booktitle = {Transactions on Machine Learning Research (TMLR), Oct 2025}, month = oct, year = {2025}, selected = true, num_co_first_author = {2}, } - Arxiv
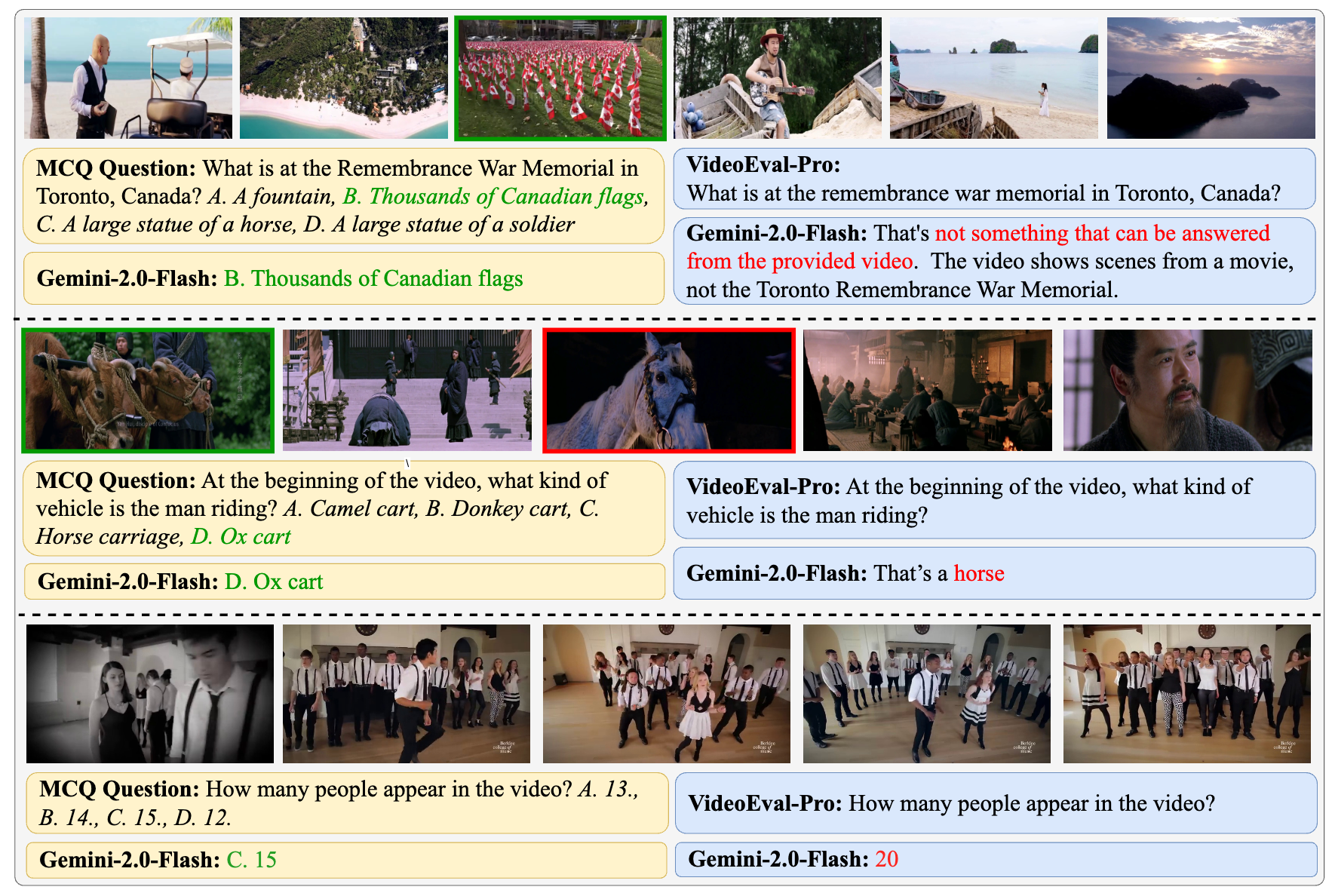 VideoEval-Pro: Robust and Realistic Long Video Understanding EvaluationWentao Ma , Weiming Ren , Yiming Jia , and 4 more authorsIn arxiv preprint, May 2025
VideoEval-Pro: Robust and Realistic Long Video Understanding EvaluationWentao Ma , Weiming Ren , Yiming Jia , and 4 more authorsIn arxiv preprint, May 2025 Large multimodal models (LMMs) have recently emerged as a powerful tool for long video understanding (LVU), but existing benchmarks have significant limitations. Most current benchmarks rely heavily on multiple-choice questions (MCQs) with inflated evaluation results due to guessing, and many questions have strong priors that allow models to answer without watching the entire video. We propose VideoEval-Pro, a new benchmark with open-ended short-answer questions that assess segment-level and full-video understanding through perception and reasoning tasks. By evaluating 21 video LMMs, we discovered significant performance drops (>25\%) on open-ended questions compared to MCQs, higher MCQ scores do not correlate with higher open-ended scores, and VideoEval-Pro benefits more from increased input frames compared to other benchmarks. Our goal is to provide a more realistic and reliable measure of long video understanding.
@inproceedings{ma2025videoeval, title = {VideoEval-Pro: Robust and Realistic Long Video Understanding Evaluation}, author = {Ma, Wentao and Ren, Weiming and Jia, Yiming and Li, Zhuofeng and Nie, Ping and Zhang, Ge and Chen, Wenhu}, booktitle = {arxiv preprint}, month = may, year = {2025}, github = {TIGER-AI-Lab/VideoEval-Pro}, huggingface = {https://huggingface.co/papers/2505.14640}, twitter = {https://x.com/zhuofengli96475/status/1963216180438814901}, selected = true, } - TMLR 2025
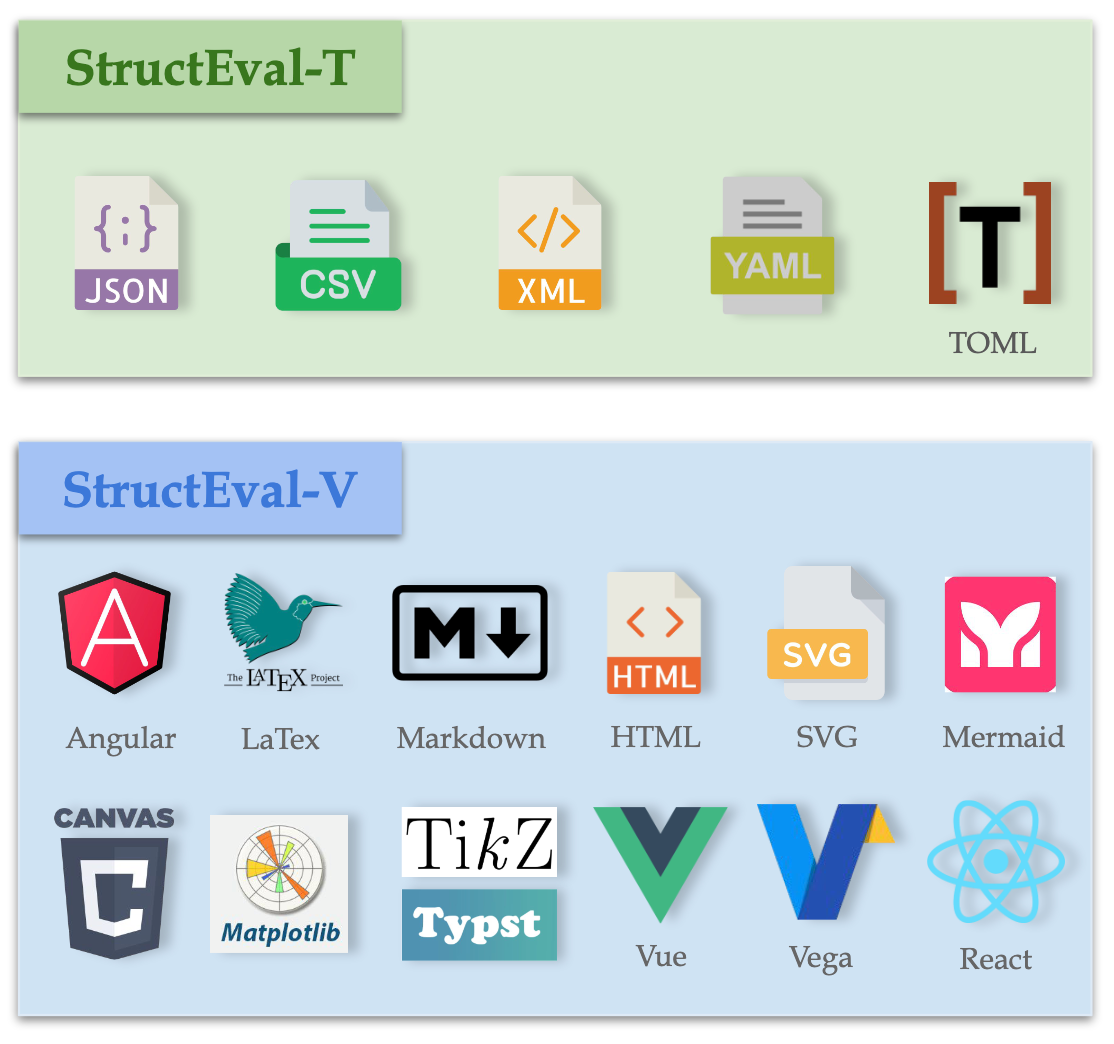 StructEval: Benchmarking LLMs’ Capabilities to Generate Structural OutputsJialin Yang , Dongfu Jiang , Lipeng He , and 8 more authorsIn Transactions on Machine Learning Research (TMLR), Dec 2025, May 2025
StructEval: Benchmarking LLMs’ Capabilities to Generate Structural OutputsJialin Yang , Dongfu Jiang , Lipeng He , and 8 more authorsIn Transactions on Machine Learning Research (TMLR), Dec 2025, May 2025 As Large Language Models (LLMs) become integral to software development workflows, their ability to generate structured outputs has become critically important. We introduce StructEval, a comprehensive benchmark for evaluating LLMs’ capabilities in producing both non-renderable (JSON, YAML, CSV) and renderable (HTML, React, SVG) structured formats. Unlike prior benchmarks, StructEval systematically evaluates structural fidelity across diverse formats through two paradigms: generation tasks and conversion tasks. Our benchmark encompasses 18 formats and 44 types of task, with novel metrics for format adherence and structural correctness. Results reveal significant performance gaps, even state-of-the-art models like o1-mini achieve only 75.58 average score.
@inproceedings{yang2025structeval, title = {StructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs}, author = {Yang, Jialin and Jiang, Dongfu and He, Lipeng and Siu, Sherman and Zhang, Yuxuan and Liao, Disen and Li, Zhuofeng and Zeng, Huaye and Jia, Yiming and Wang, Haozhe and others}, booktitle = {Transactions on Machine Learning Research (TMLR), Dec 2025}, month = may, year = {2025}, github = {https://github.com/TIGER-AI-Lab/StructEval}, huggingface = {https://huggingface.co/papers/2505.20139}, selected = true, }




2024
- NeurIPS 2024
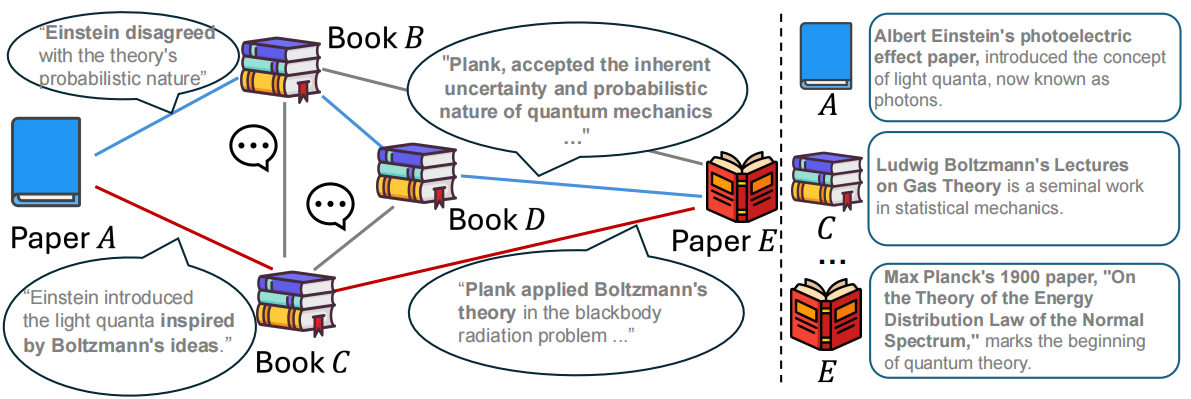 Teg-db: A comprehensive dataset and benchmark of textual-edge graphsZhuofeng Li , Zixing Gou , Xiangnan Zhang , and 6 more authorsIn Advances in Neural Information Processing Systems, Dec 2024
Teg-db: A comprehensive dataset and benchmark of textual-edge graphsZhuofeng Li , Zixing Gou , Xiangnan Zhang , and 6 more authorsIn Advances in Neural Information Processing Systems, Dec 2024 Text-Attributed Graphs (TAGs) augment graph structures with natural language descriptions, but existing datasets primarily feature textual information only at nodes. We introduce TEG-DB, a comprehensive benchmark of textual-edge datasets with rich descriptions on both nodes and edges, spanning domains like citation and social networks. We conducted benchmark experiments to evaluate how current techniques including pre-trained language models and graph neural networks can utilize textual node and edge information. Our goal is to advance research in textual-edge graph analysis and provide deeper insights into complex real-world networks.
@inproceedings{li2024teg, title = {Teg-db: A comprehensive dataset and benchmark of textual-edge graphs}, author = {Li, Zhuofeng and Gou, Zixing and Zhang, Xiangnan and Liu, Zhongyuan and Li, Sirui and Hu, Yuntong and Ling, Chen and Zhang, Zheng and Zhao, Liang}, booktitle = {Advances in Neural Information Processing Systems}, volume = {37}, pages = {60980--60998}, month = dec, year = {2024}, github = {Zhuofeng-Li/TEG-Benchmark}, huggingface = {https://huggingface.co/papers/2406.10310}, selected = true, } - Arxiv
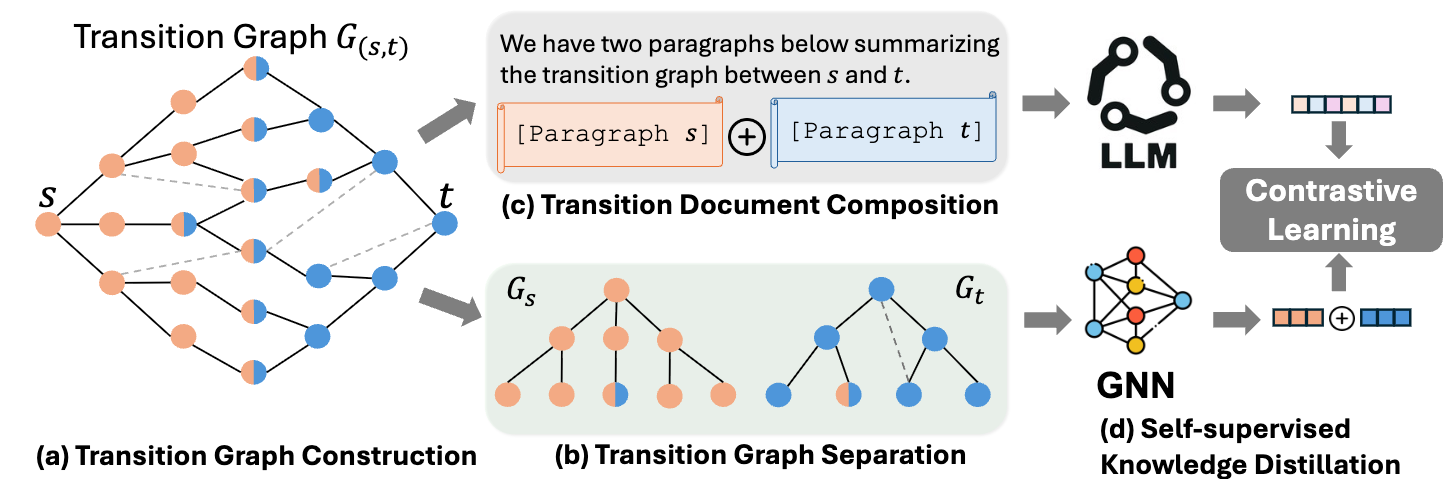 Link prediction on textual edge graphsChen Ling* * , Zhuofeng Li* * , Yuntong Hu , and 5 more authorsIn arxiv preprint, May 2024
Link prediction on textual edge graphsChen Ling* * , Zhuofeng Li* * , Yuntong Hu , and 5 more authorsIn arxiv preprint, May 2024 Textual-edge Graphs (TEGs) are graphs with rich text annotations on edges, capturing contextual information among entities. Existing approaches often struggle to fully capture edge semantics and graph topology, especially in link prediction tasks. We propose Link2Doc, a novel framework that summarizes neighborhood information between node pairs as a human-written document, preserves both semantic and topological information, and uses a self-supervised learning model to enhance graph neural networks’ text understanding. Empirical evaluations across four real-world datasets demonstrate that Link2Doc achieves generally better performance against existing edge-aware GNNs and pre-trained language models in predicting links on TEGs.
@inproceedings{ling2024link, title = {Link prediction on textual edge graphs}, author = {Ling, Chen and Li, Zhuofeng and Hu, Yuntong and Zhang, Zheng and Liu, Zhongyuan and Zheng, Shuang and Pei, Jian and Zhao, Liang}, booktitle = {arxiv preprint}, month = may, year = {2024}, num_co_first_author = {2}, } - Arxiv
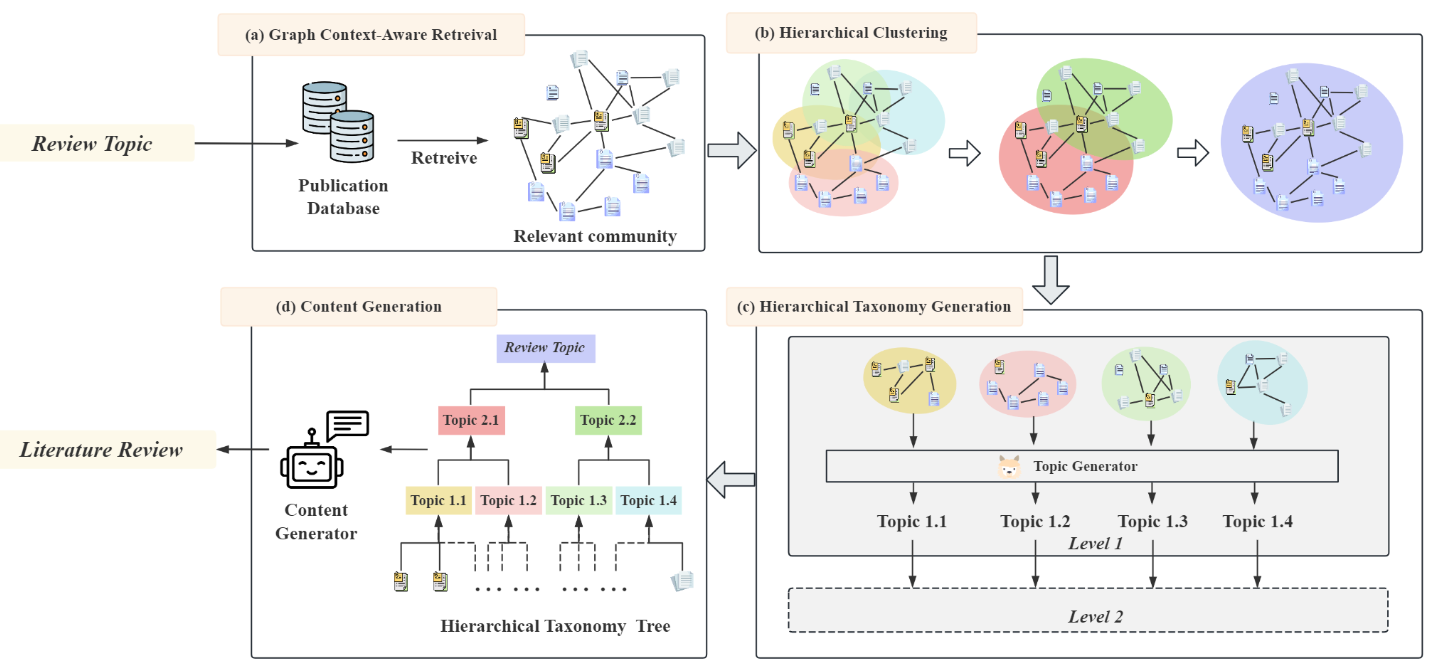 Hireview: Hierarchical taxonomy-driven automatic literature review generationYuntong Hu , Zhuofeng Li , Zheng Zhang , and 4 more authorsIn arxiv preprint, Jul 2024
Hireview: Hierarchical taxonomy-driven automatic literature review generationYuntong Hu , Zhuofeng Li , Zheng Zhang , and 4 more authorsIn arxiv preprint, Jul 2024Literature reviews are essential for understanding research fields and identifying knowledge gaps, but manually creating comprehensive reviews is time-consuming and labor-intensive. We present HiReview, a hierarchical taxonomy-driven automatic literature review generation system that leverages large language models to create structured, comprehensive reviews. Our approach uses a multi-level taxonomic framework to organize papers and generate coherent, well-structured literature reviews that capture the essential aspects of a research domain.
@inproceedings{hu2024hireview, title = {Hireview: Hierarchical taxonomy-driven automatic literature review generation}, author = {Hu, Yuntong and Li, Zhuofeng and Zhang, Zheng and Ling, Chen and Kanjiani, Raasikh and Zhao, Boxin and Zhao, Liang}, booktitle = {arxiv preprint}, month = jul, year = {2024}, } - CIKM 2024
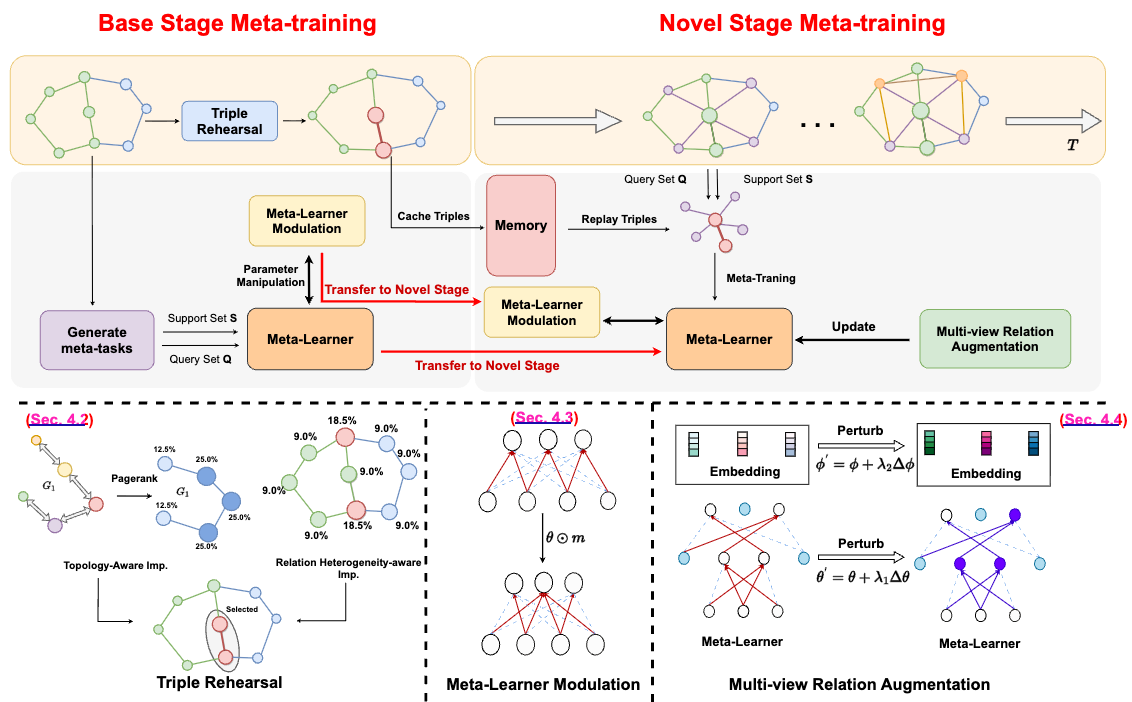 Learning from novel knowledge: Continual few-shot knowledge graph completionZhuofeng Li , Haoxiang Zhang , Qiannan Zhang , and 2 more authorsIn Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, Oct 2024
Learning from novel knowledge: Continual few-shot knowledge graph completionZhuofeng Li , Haoxiang Zhang , Qiannan Zhang , and 2 more authorsIn Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, Oct 2024Knowledge graph completion has been increasingly recognized as a vital approach for uncovering missing knowledge and addressing the incompleteness issue in KGs. To enhance inference on rare relations and mitigate the impact of the long-tail distribution, the dominant strategy designs few-shot models following the meta-learning paradigm. However, these approaches typically operate under the assumption that KGs are available instantly, disregarding the newly emerging relations during KG enrichment. We propose a novel framework designed to equip the few-shot model with the ability to learn sequentially from novel relations through data-level rehearsal and model-level modulation to address catastrophic forgetting, alongside multi-view relation augmentation aimed at resolving the issue of insufficient novel relations.
@inproceedings{li2024learning, title = {Learning from novel knowledge: Continual few-shot knowledge graph completion}, author = {Li, Zhuofeng and Zhang, Haoxiang and Zhang, Qiannan and Kou, Ziyi and Pei, Shichao}, booktitle = {Proceedings of the 33rd ACM International Conference on Information and Knowledge Management}, pages = {1326--1335}, month = oct, year = {2024}, selected = true, }
